FAQ
FAQ – Perguntas frequentes relacionadas ao Serviço de Apoio ao Desenvolvimento Científico.
2. Como criar uma conta no cluster?
3. Como renovar minha conta no cluster?
4. Como acessar o ambiente do cluster?
5. Como solicitar instalação de software no cluster?
6. Como solicitar ajuda em meu script .pbs?
8. Como solicitar o desenvolvimento de um software científico?
9. Como solicitar alterações em um software científico?
10. Como solicitar o Apoio a Projetos de Pesquisa?
11. Minha solicitação está com status “PENDENTE”, como proceder?
12. Qual a quantidade de memória RAM e o número de processadores para a minha análise?
Por que meu job está sendo finalizado precocemente pelo PBS por utilização de RAM?
1. Quem pode usar o cluster?
Para ter acesso ao cluster é necessário possuir vínculo ativo com a instituição (UFV), ser cadastrado como membro em projeto registrado e vigente na Pró-Reitoria de Pesquisa e Pós-Graduação (PPG/UFV).
2. Como criar uma conta no cluster?
Existem duas formas para se criar conta no Cluster:
1º – O interessado acessa o sistema de criação de contas, escolhe o projeto e solicita a conta. Após solicitada, será enviado e-mail para o líder do projeto com a solicitação de autorização. O líder deve assinalar seu aceite para que a conta possa ser criada.
2º O Líder do projeto acessa o sistema, escolhe o projeto e solicita a criação de conta para os membros do projeto que ele desejar.
Link do sistema de abertura de contas: https://www3.dti.ufv.br/dti/cluster/
3. Como renovar minha conta no cluster?
Para continuar a utilizar o cluster após a expiração da conta, o usuário com vínculo ativo com a instituição, deve solicitar a renovação da sua conta por prazo determinado.
Para solicitar a renovação:
1º Clique aqui para acessar o sistema de abertura de contas.
2º Logue no sistema com as suas credenciais de acesso.
3º Localize a conta expirada.
4º Clique em ‘Detalhes’ conforme imagem abaixo:
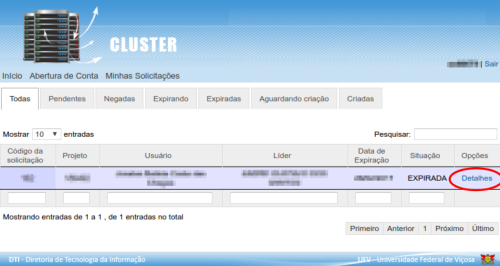
5º Na página que irá abrir, no canto superior esquerdo há o botão ‘Solicitar Prorrogação’. Basta clicar neste botão e dar andamento à solicitação:

6º Após efetivar a solicitação, o líder do projeto cadastrado no sistema de criação de contas receberá um e-mail e deve aprovar a solicitação no mesmo sistema. Após a aprovação do líder o cadastro é atualizado imediatamente.
4. Como acessar o ambiente do cluster?
Veja instruções em nosso site: https://dct.uf.br/uso-do-ambiente/
5. Como solicitar instalação de software no cluster?
Para solicitar a instalação de um software no cluster, é necessário que o solicitante tenha sua conta ativa no sistema do cluster. A solicitação deve ser registrada por meio do Sistema de Abertura e Acompanhamento de Chamados da DTI, contendo as seguintes informações sobre o software:
- Nome do software
- Versão desejada
- Link para download
- Tipo de licença (caso aplicável)
Atenção: o software deve ser compatível com o sistema operacional Linux, pois apenas softwares que atendem a esse requisito serão instalados.
6. Como solicitar ajuda em meu script .pbs?
Para solicitar auxílio na construção e submissão do script .pbs, é necessário que o solicitante tenha sua conta ativa no sistema do cluster. A solicitação deve ser registrada por meio do Sistema de Abertura e Acompanhamento de Chamados da DTI, contendo as seguintes informações:
- Nome do script
- Caminho onde o script está armazenado
- Descrição clara do problema ou dúvida
Importante: Nosso suporte técnico está limitado à orientação sobre a especificação de variáveis de ambiente, formas de uso e aspectos relacionados aos requisitos de submissão do gerenciador de jobs e ao funcionamento do sistema de filas. Não oferecemos suporte para detalhes técnicos ou uso específico de softwares externos.
7. Ao submeter um job ele é automaticamente encerrado e recebi o e-mail de violação de recurso devido a utilização incorreta de processador, o que fazer?
Neste caso, o job foi finalizado porque a quantidade de processadores utilizada excedeu o número especificado no script .pbs, o que viola as políticas de alocação de recursos. Para corrigir o problema e evitar que isso ocorra novamente, siga estas etapas:
- A diretiva
#PBS -lno script, informando o número exato de processadores desejado - A configuração do software utilizado, garantindo que ele também esteja configurado para usar essa mesma quantidade de processadores, por meio dos argumentos corretos na linha de comando
Após realizar esses ajustes, tente submeter novamente seu script .pbs.
Sobre a reserva e uso de recursos:
O cluster possui um processo de monitoramento contínuo que verifica se cada job está utilizando apenas os recursos previamente reservados. Caso seja detectado o uso indevido – como o consumo de mais CPUs do que o solicitado – o job é automaticamente encerrado para garantir a integridade e o desempenho do ambiente compartilhado.
Exemplo prático:
Um job foi submetido solicitando 20 processadores (equivalente a 2000%, considerando que cada processador representa 100%). No entanto, durante a execução, o job passou a utilizar 48 processadores (4711.1%). Esse uso excedente consome recursos que estão reservados para outros usuários, podendo comprometer suas análises. Por isso, o job é automaticamente finalizado e o usuário recebe uma notificação.
Diferença entre Reserva e Uso de Recursos:
É fundamental compreender a distinção entre reservar e utilizar recursos. Vamos ilustrar com o exemplo de processadores – o mesmo conceito se aplica à memória.
- A reserva de recursos é feita por meio da diretiva
#PBS -lno script. Exemplo:
#PBS -l nodes=1:ppn=4,mem=10gb
Nesse caso, o sistema de filas reserva 4 processadores e 10 GB de memória para o job.
- O uso efetivo desses recursos depende do comportamento do script e do software executado. O sistema de filas não tem como prever se o job realmente utilizará os 4 processadores solicitados, ou se tentará usar 1 ou até 30. Essa gestão deve ser feita pelo próprio script, garantindo que o uso esteja alinhado com a reserva. O seu script deve controlar isso.
Configuração de Processadores em Softwares Paralelos:
Alguns softwares oferecem parâmetros específicos para configurar a quantidade de processadores (ou número de threads) que serão utilizados durante a execução. Se esse for o caso do seu software, você pode ajustar esse valor diretamente na linha de comando, garantindo que ele esteja em conformidade com a quantidade de recursos solicitada na diretiva #PBS -l do seu script .pbs.
Para verificar se o seu software possui essa opção, consulte o manual ou utilize o comando de ajuda (--help, -h, etc.).
Softwares sem Controle de Processadores:
Há softwares paralelos (utilizam mais de 1 processador) que, por padrão, utilizam todos os processadores disponíveis na máquina, sem oferecer mecanismos para limitar esse uso. Isso pode causar problemas no cluster, pois o job acaba consumindo recursos reservados para outros usuários.
Se o seu software se enquadra nesse caso, uma alternativa eficaz é o uso do recurso cpuset, que já foi adotado com sucesso por outros usuários do cluster. Para aplicar essa solução, basta incluir os seguintes comandos no seu script .pbs:
#Habilita o carregamento de módulos
source /etc/profile.d/modules.sh
module load dct-utils/1.0
cpuset
O comando cpuset deve ser o primeiro a ser executado imediatamente após o carregamento dos módulos necessários. Isso é fundamental para garantir que o ambiente de execução esteja corretamente configurado antes da chamada ao software. O comando deve ser inserido antes da execução do software propriamente dito no script .pbs.
A abordagem recomendada é configurar diretamente no software o número de processadores ou threads a serem utilizados. A maioria dos softwares paralelos oferece parâmetros para esse ajuste – consulte o manual ou a ajuda (--help) do seu software para verificar essa possibilidade. É provável que o software que você utiliza tenha este parâmetro.
Se, mesmo após esses ajustes, o problema persistir, entre em contato com nossa equipe de suporte conforme orientado no FAQ, item 2.5.6 Como solicitar ajuda em meu script (.pbs)?
8. Como solicitar o desenvolvimento de um software científico?
Primeiramente é necessário que você possua vínculo ativo com a instituição (UFV), que o software tenha cunho científico, e seja algo que possa contribuir com o avanço da pesquisa científica da instituição. A princípio será feita uma análise de viabilidade do software, e se aprovado pela chefia do serviço SDC, será criado um novo projeto para desenvolvimento do mesmo. Caso contrário, será apresentado o parecer e as devidas justificativas para o não desenvolvimento.
A solicitação deve ser registrada por meio do Sistema de Abertura e Acompanhamento de Chamados da DTI, contendo as seguintes informações:
- Dados do solicitante: nome completo e matrícula UFV
- Informações sobre o software: um resumo do que se trata o software, incluindo sua finalidade ou área de aplicação.
9. Como solicitar alterações em um software científico?
Alterações em softwares só podem ser solicitadas quando o sistema em questão foi desenvolvido pela SDC e o responsável possua vínculo ativo com a UFV.
A solicitação deve ser registrada por meio do Sistema de Abertura e Acompanhamento de Chamados da DTI, contendo as seguintes informações:
- Dados do solicitante: nome completo e matrícula UFV
- Informações sobre o software: nome do sistema e um resumo da alteração desejada.
10. Como solicitar o Apoio a Projetos de Pesquisa?
A solicitação deve ser registrada por meio do Sistema de Abertura e Acompanhamento de Chamados da DTI, contendo as seguintes informações:
- Dados do solicitante: nome completo e matrícula UFV
- Informações do projeto: detalhes sobre o projeto e, se possível, o edital relacionado
11. Minha solicitação está com status “PENDENTE”, como proceder?
A solicitação cujo status é “PENDENTE”, significa que está pendente aprovação do líder do projeto, ele receberá um e-mail automático do cluster/UFV solicitando que entre no sistema do cluster e faça a avaliação, caso aprovada por ele, iremos automaticamente renovar a conta. No contrário o usuário será notificado que a conta não foi renovada por reprovação do líder. Em relação ao e-mail enviado ao líder, não tem como reenviá-lo, pois é automático, caso ele não tenha mais o e-mail basta entrar no sistema do cluster e fazer a avaliação da solicitação.
12. Qual a quantidade de memória RAM e o número de processadores para a minha análise?
Infelizmente, não há uma resposta única e direta para essa pergunta, pois diversos fatores influenciam o consumo de recursos computacionais. Não é possível afirmar simplesmente: “utilize x processadores e y GB de RAM”.
Algumas variáveis importantes a serem consideradas incluem:
- Capacidade de paralelização do software: o programa realiza processamento paralelo ou é sequencial?
- Características dos dados de entrada: o volume, a complexidade e o formato dos dados podem impactar significativamente o uso de CPU e memória.
- Estrutura interna do software: a forma como o desenvolvedor implementou o uso de memória e threads pode variar bastante entre aplicações.
- Comportamento do ambiente de filas do cluster:
- Execução de múltiplas análises em um único script
.pbs - Tempo de execução de cada tarefa
- Distribuição de recursos entre jobs simultâneos
- Execução de múltiplas análises em um único script
A seguir, apresentamos alguns parâmetros e orientações que podem ajudar na melhor utilização do ambiente do Cluster/UFV. Este conteúdo complementa as informações disponíveis em nossa página oficial.
Entenda como atuam Processador e Memória (RAM)
Antes de definir os recursos ideais para executar uma aplicação no cluster, é importante compreender como atuam o processador e a memória RAM.
A RAM é responsável por armazenar temporariamente os dados que o processador precisa acessar durante a execução de um software e fazer os procedimentos inerentes do software para aquela análise em questão. Ela é caracterizada principalmente por dois fatores: velocidade e capacidade de armazenamento. No contexto desta questão, o que é mais relevante é a capacidade.
A quantidade de RAM necessária pode variar de acordo com os dados de entrada da aplicação. Ou seja, um mesmo software pode demandar diferentes volumes de memória dependendo do tamanho, complexidade ou formato dos dados processados. Ou seja, em geral o uso de RAM dependerá dos dados de entrada.
O processador está mais associado à velocidade de execução da aplicação. Podemos classificar o processamento em dois tipos:
- Sequencial: utiliza apenas um núcleo de processamento
- Paralelo: distribui a carga entre múltiplos núcleos ou threads
Diferentemente da RAM, que depende fortemente dos dados que serão carregados, o número de processadores utilizados não depende diretamente dos dados de entrada, mas sim da capacidade do software de realizar processamento paralelo. Muitos softwares paralelos oferecem parâmetros para definir a quantidade de processadores, núcleos (cores) ou threads a serem utilizados, geralmente por meio de argumentos na linha de comando.
Entenda a diferença de Processamento Sequencial e Processamento Paralelo
Na computação, distinguimos duas formas básicas de processamento: sequencial e paralelo.
- Processamento sequencial: Tradicionalmente, os softwares são desenvolvidos para executar instruções uma após a outra, em um único fluxo de execução. Cada etapa depende da conclusão da anterior, o que pode limitar o desempenho em tarefas mais complexas.
- Processamento paralelo: Nesse modelo, múltiplos cálculos são realizados simultaneamente, de forma paralela (ou concorrente), em diferentes fluxos de execução. Partes do software são distribuídas entre vários núcleos ou processadores, reduzindo significativamente o tempo total de processamento (tempo de relógio). Essa abordagem é amplamente utilizada em ambientes de computação de alto desempenho (HPC).
Para que o processamento paralelo ocorra, o software precisa ser especificamente projetado e implementado com técnicas que permitam essa execução simultânea. O ambiente do cluster não paraleliza automaticamente um software sequencial.
Especificação de Processadores no Script
Nem todo software realiza processamento paralelo. Quando o software oferece essa funcionalidade, é responsabilidade do usuário definir corretamente a quantidade de processadores, núcleos (cores) ou threads a serem utilizados.
Cada software possui sua própria forma de configurar o paralelismo – geralmente por meio de parâmetros na linha de comando ou arquivos de configuração. Por isso, é essencial que o usuário consulte o manual ou ajuda (--help) do programa para entender como especificar esses recursos corretamente no script .pbs.
Um pouco sobre o sistema de filas no cluster (PBS)
O PBS (Portable Batch System) é o software responsável por gerenciar as submissões de análises no Cluster/UFV. Entre suas principais funções estão:
- Gerenciar as filas de jobs que aguardam execução
- Controlar o uso dos recursos computacionais disponíveis (processadores, memória, nós)
- Definir, a cada ciclo de verificação, quais jobs serão executados
Atualmente, o sistema de filas opera com base na ordem de inserção dos jobs. Ou seja, em geral (mas não necessariamente), o job que foi submetido primeiro será executado primeiro – desde que haja recursos disponíveis para atender aos requisitos especificados no script .pbs (como memória e número de processadores).
Se, durante um ciclo de verificação, o PBS não encontrar um nó que atenda aos requisitos de um job, ele mantém o job na fila e tenta executar o próximo da lista. Isso garante que os recursos do cluster sejam utilizados de forma eficiente e contínua.
Devido ao funcionamento descrito acima, é essencial ajustar corretamente a quantidade de processadores solicitados:
- Se o software não realiza processamento paralelo, especifique apenas 1 processador no script
.pbs. Isso evita:- Que seu job (e outros) fiquem mais tempo na fila desnecessariamente
- O desperdício de recursos, já que apenas um núcleo será utilizado
- Se o software realiza processamento paralelo, você pode solicitar mais de 1 processador. No entanto, essa decisão exige atenção e uma decisão importante a ser tomada pelo usuário:
- Solicitar menos processadores pode permitir que o job entre em execução mais rapidamente, mas o tempo total de processamento será maior
- Solicitar mais processadores pode acelerar a execução, mas o job poderá demorar mais para iniciar, pois o PBS aguardará a disponibilidade dos recursos solicitados
A escolha ideal depende de:
- O tempo estimado para sua análise
- O nível de ocupação atual do cluster
- A eficiência paralela do seu software
Em alguns casos, pode valer a pena especificar uma quantidade maior de processadores, se sua análise demanda muito tempo. Outras vezes especificar uma quantidade menor vale a pena se a análise não demanda muito tempo de processamento.
Em períodos de alta demanda, solicitar muitos processadores pode fazer com que seu job permaneça na fila por mais tempo.
Dica: O comando hinfo pode ajudar na definição dos recursos ideais. Ele exibe os recursos de memória e processadores disponíveis em cada nó ativo do cluster, permitindo uma escolha mais informada na configuração do seu script.
Composição de análises em um mesmo job:
Em determinados casos, pode ser vantajoso agrupar mais de uma análise dentro de um único script .pbs. No entanto, essa prática não é uma regra geral – sua aplicabilidade depende diretamente das características e demandas específicas da pesquisa.
Pesquisas que envolvem grande volume de execuções, como variações de parâmetros ou múltiplos conjuntos de dados, tendem a se beneficiar dessa abordagem. Isso ocorre porque o PBS (sistema de gerenciamento de filas do cluster) limita a quantidade de jobs por usuário. Para mais detalhes, consulte as Políticas de Uso. Assim, colocando mais de uma análise em um mesmo job há um melhor aproveitamento do cluster quando esta é uma característica relevante para a pesquisa.
Essa estratégia é especialmente útil quando as análises são independentes entre si e podem ser executadas sequencialmente ou em paralelo dentro do mesmo ambiente de execução.
Entendendo a diferença entre Reserva e Uso de Recursos:
É fundamental compreender a distinção entre reserva e uso de recursos no ambiente do cluster.
O PBS (Portable Batch System) é o sistema responsável pela gerência de recursos, mas não executa o processamento paralelo nem controla a alocação de memória. Essas tarefas são responsabilidade do software utilizado e da forma como o script .pbs é configurado.
- O PBS reserva os recursos solicitados por meio da diretiva
#PBS -lno script. - O uso efetivo desses recursos depende do comportamento do software e da configuração feita pelo usuário.
- Se o software não realiza processamento paralelo, solicitar mais de um processador será ineficiente e poderá prolongar o tempo na fila.
- O processamento paralelo deve ser feito explicitamente pelo software e configurado adequadamente quando for utilizá-lo.
- O uso de recursos é de responsabilidade do script/software e é responsabilidade do usuário a correta configuração dentro do seu script.
Além disso, o PBS possui um monitor interno que verifica constantemente se os jobs estão utilizando apenas os recursos reservados. Se um job exceder o uso – por exemplo, consumir mais CPUs ou memória do que o solicitado – ele será finalizado automaticamente.
Para entender melhor, considere o seguinte exemplo fictício: um job é submetido solicitando 1 processador, mas durante a execução utiliza 48 processadores. Isso pode ocorrer em softwares paralelos que, por padrão, usam todas as CPUs disponíveis no nó. Se o usuário não configurar corretamente o número de processadores no script, o job compromete os recursos de outros usuários e será encerrado pelo PBS. O usuário deverá conferir e corrigir o seu script .pbs.
A reserva é feita na diretiva #PBS -l:
#PBS -l nodes=1:ppn=4,mem=10gb
Nesse caso, o PBS reservará 4 processadores e 10 GB de RAM, conforme solicitado na diretiva. O job só será executado quando houver um nó com esses recursos disponíveis. O PBS somente colocará o job em execução quando tiver pelo menos 4 processadores e 10gb de RAM livres em um nó de cálculo. O PBS não sabe como o software utilizará esses recursos (se o seu script irá utilizar 1 ou 30 processadores). Cabe ao usuário garantir que o script e o software estejam configurados para usar exatamente o que foi reservado.
A maioria dos softwares paralelos oferece parâmetros para definir o número de processadores, threads ou núcleos. Esses valores devem ser informados na linha de comando ou em arquivos de configuração, conforme a documentação do software. Consulte sempre o manual ou ajuda (--help) do programa para saber como configurar corretamente o paralelismo.
Após a execução de um job, sempre verifique:
- Seu e-mail institucional
- O e-mail cadastrado no script
- Os arquivos de saída gerados pelo PBS
Esses registros informam o motivo da finalização do job, caso ocorra. Se o problema for relacionado à CPU ou memória, ajuste:
- A diretiva de alocação no script
.pbs - Os parâmetros internos do software para refletir corretamente os recursos reservados
Especificação de processador e memória na diretiva #PBS -l (reserva) e explicitamente na chamada do software (uso)
Ao configurar um script .pbs, é essencial entender a diferença entre reserva de recursos (feita na diretiva #PBS -l) e o uso efetivo desses recursos (definido na chamada do software).
A especificação de processadores geralmente é feita como argumento na execução do software – desde que ele suporte processamento paralelo. Nesses casos, é fundamental que o número de processadores:
- Seja corretamente informado na diretiva
#PBS -l - Seja compatível com o valor passado ao software na linha de comando
Essa correspondência evita desperdício de recursos e garante que o job utilize o que foi reservado.
A especificação de memória é mais complexa, pois depende diretamente dos dados de entrada. O valor deve ser estimado empiricamente e informado ao PBS. Se o job for finalizado por exceder a memória reservada, será necessário:
- Ajustar o valor solicitado
- Submeter o job novamente
Alguns usuários, diante da dificuldade de estimar corretamente, optam por superestimar a memória. Embora isso evite finalizações por falta de recursos, pode aumentar o tempo de espera na fila, já que o PBS aguardará a disponibilidade de uma quantidade maior de RAM.
Lembre-se: o uso de RAM pode oscilar ao longo da execução, dependendo da dinâmica da análise.
O comando jinfo pode auxiliar na análise do uso real de recursos. Veja abaixo um exemplo de saída que evidencia desperdício:
# Listando módulos que contenham a palava "java" $ jinfo 12345678 Getting job '12345678' Job name: analiseTeste Job id: '12345678' Submit args: exemplo.pbs CPU required: 1000.00% CPU used: 107.00% RAM required: 8192.00MB RAM used: 3958.73MB Warning: your job, at this moment, uses less processors than was required. Info: CPU utilization is OK at this moment.
Neste exemplo:
- O usuário solicitou 10 processadores (ppn=10), mas o job está utilizando apenas 1. Assim, se não houver nenhum fato novo no script que aumente o número de cpus, estamos com 9 cpus alocadas para o job sem uso durante o período se sua execução. Ou em outras palavras, estamos com 9 cpus desperdiçados.
- Foram reservados 8 GB de RAM, mas apenas ~4 GB estão sendo utilizados.
Esse tipo de configuração resulta em desperdício de recursos, o que afeta:
- O tempo de espera na fila, já que o PBS considera os recursos como ocupados, mesmo sem uso real
- A disponibilidade de recursos para outros jobs (inclusive do mesmo usuário)
- O tempo de espera na fila, já que o PBS considera os recursos como ocupados, mesmo sem uso real
Boas Práticas
- Solicite apenas os recursos necessários com base em testes prévios
- Verifique se o software permite configurar o número de processadores ou threads
- Consulte o manual ou ajuda (
--help) do software para ajustar corretamente os parâmetros - Utilize o
jinfo
13. Por que meu job está sendo finalizado precocemente pelo PBS por utilização de RAM?
Seu job pode ser finalizado (ou “killed”) pelo gerenciador de recursos PBS quando utiliza mais memória RAM do que a quantidade especificada na diretiva #PBS -l mem= do script .pbs.
O PBS monitora constantemente se o uso de memória está dentro do limite reservado. Esse controle é essencial para garantir que seu job não consuma recursos alocados para outros usuários, evitando interferências e prejuízos à execução de outros processos no mesmo nó de cálculo.
Você pode verificar se o job foi encerrado por uso excessivo de memória utilizando os seguintes comandos:
jinfo <job_id>: exibe informações detalhadas sobre o uso de CPU e memória do jobqstat -xf <job_id>: mostra o status completo do job, incluindo o motivo da finalização- verificando detalhes no e-mail cadastrado no script .pbs
O que posso fazer para resolver esse problema?
A quantidade de memória necessária depende de diversos fatores, como os dados de entrada, os algoritmos internos do software e os parâmetros utilizados. Diferente da CPU (por xemplo, com argumetnos como --threads ou --cores), a maioria dos programas não permite limitar diretamente o uso de RAM, tornando a estimativa mais empírica.
Aqui estão algumas sugestões:
- Aumentar a memória solicitada: edite seu script
.pbse aumente o valor na diretiva#PBS -l mem=. Exemplo: se estava solicitandomem=8gb, tentemem=16gbou mais, conforme a disponibilidade de recursos no cluster. - Consultar a documentação do software: verifique se o programa oferece parâmetros que possam reduzir o consumo de memória, como controle de cache, tamanho de lote, ou otimizações específicas.
- Reduzir o número de processadores: diminuir o valor de
ppn=na diretiva#PBS -l nodes=1:ppn=pode ajudar, já que alguns softwares consomem menos RAM com menos CPUs. Isso pode aumentar o tempo de execução, mas também pode reduzir o tempo de espera na fila, pois jobs menores são alocados mais rapidamente. - Testar e validar: como administradores, não temos controle sobre os algoritmos ou dados utilizados. Por isso, a configuração ideal de RAM e CPU deve ser testada empiricamente por você. Experimente diferentes combinações e monitore o comportamento do job com
jinfo
Por que não é possível prever exatamente quanta RAM devo solicitar?
A demanda de memória varia conforme:
- Dados de entrada: tamanho, formato e complexidade
- Algoritmos do software: cada programa tem sua própria forma de alocar e liberar memória
- Parâmetros de execução: alguns argumentos podem aumentar ou reduzir o uso de RAM
Recomendamos consultar a documentação oficial do software ou buscar apoio em fóruns especializados para entender como otimizar o uso de memória no seu caso específico.
Como balancear tempo de execução e uso de recursos?
- Mais recursos (CPU/RAM): Acelera a execução, mas pode aumentar o tempo de espera na fila, já que jobs com maiores demandas de recursos demoram mais para serem alocados.
- Menos recursos: Pode aumentar o tempo de execução, mas reduz a espera na fila, permitindo que o job inicie mais rapidamente.
Teste diferentes configurações para encontrar o equilíbrio ideal entre tempo de execução e uso de recursos, considerando as restrições do cluster e as necessidades do seu job.