Uso do Ambiente
O uso do cluster da UFV para atividades de pesquisa, no que diz respeito aos aspectos computacionais, se resume às seguintes atividades:
- Criação/Renovação da conta pessoal de utilização do cluster
- Leitura e Compreensão das Políticas de Uso do Cluster
- Conexão Remota e Transferência de arquivos no cluster
- Construir e submeter o script pbs
- Monitorar os jobs e conferir os resultados
Estas atividades serão detalhadas abaixo.
Notação de Substituição em Comandos
Ao longo deste material, utilizaremos a notação <info> para indicar campos que devem ser substituídos pelo valor correspondente ao contexto de uso. Essa convenção facilita a leitura e ajuda a identificar os pontos onde o usuário deve inserir suas próprias informações.
Por exemplo, considere o seguinte comando:
qstat -f <job_id>
Neste caso, o campo < representa o identificador do job que você deseja consultar. Para que o comando funcione corretamente, é necessário substituir job_id><job_id> pelo número real do job em execução ou já finalizado.
Neste exemplo, se você deseja consultar informação sobre o job de identificador 123456, o correto seria:
qstat -f 12345
Assim estaria errado:
qstat -f <123456>
Essa notação será utilizada em diversos trechos do material para indicar campos variáveis que devem ser ajustados conforme o seu contexto de uso.
1. Criação/Renovação da Conta Pessoal
Elaboramos neste link um tutorial completo com orientações passo a passo para que você possa solicitar a criação da sua conta pessoal de acesso ao cluster. O mesmo material também traz instruções sobre como renovar sua conta, caso ela tenha expirado.
2. Leitura e Compreensão das Políticas de Uso do Cluster
As políticas de uso atualizadas que regem o uso do cluster da UFV – complementares àquelas apresentadas no momento da criação da sua conta – estão disponíveis para consulta em: https://dct.ufv.br/politicas.
É fundamental que todos os usuários estejam atentos a essas diretrizes, com especial atenção para a proibição do compartilhamento de credenciais de acesso e responsabilidade individual pela proteção, backup em mídia externa e gestão dos dados, conforme as boas práticas de segurança da informação.
3. Conexão Remota e Transferência de arquivos no cluster
A conexão remota e a transferência de arquivos no cluster são operações fundamentais para o uso eficiente dos recursos computacionais disponíveis.
Por meio da conexão remota, o usuário pode acessar o ambiente do cluster diretamente de sua máquina pessoal, permitindo a execução de tarefas e monitoramento de jobs e manipulação de dados.
Já a transferência de arquivos viabiliza o envio e recebimento de documentos, scripts e resultados entre o computador local e o cluster, garantindo a continuidade dos trabalhos e viabilizando o backup seguro de dados na máquina pessoal do usuário.
Para consultar os detalhes técnicos dessas operações:
- Acesse o Sistema Cluster.
- Autentique no sistema com as suas credenciais de acesso institucionais.
- Localize a sua conta criada.
- Clique no link
Detalhes - Na seção
Detalhes da Solicitação, estarão disponíveis:- Os dados de acesso para conexão remota
- As instruções completas para realizar a transferência de arquivos entre sua máquina e o cluster.
4. Construção de script pbs e submissão de trabalhos
Toda análise a ser executada no cluster basicamente consiste em um conjunto de passos onde um determinado software é utilizado para realizar uma tarefa sobre os dados de entrada.
Por isso, a execução das análises no cluster devem ser feitas utilizando scripts, que consistem de um conjunto de comandos formando um roteiro. Normalmente estes scripts são elaborados em shell script.
Os scripts são construídos no head node. Ou copiados da sua máquina pessoal para o head node. Uma vez no head node, eles são submetidos para o sistema gerenciador de recursos, que é o PBS (conforme será mostrado adiante). Porém, os scripts não são executados no head node. Os scripts são executados, de forma transparente, nas máquinas denominadas nós escravos ou nós de cálculo.
Para serem executados nos nós de cálculo estes scripts:
- Especificam os recursos que serão necessários para rodar a análise. Como exemplo de recursos temos: quantidade de processador, quantidade de memória e tempo máximo de execução.
- E, são submetidos para as filas de processamento utilizando o gerenciador de recursos.
O sistema gerenciador de recursos, é o responsável pelo controle de recursos disponíveis no cluster e pela execução e monitoramento dos trabalhos (ou jobs). No cluster utilizamos o OpenPBS como software gerenciador de recursos. E, por isso, chamamos estes scripts de “scripts pbs”, para fazer a associação com o OpenPBS. E, também denominaremos o OpenPBS apenas como PBS por simplicidade de denominação.
Não é permitido acesso interativo aos nós de cálculo, estando os mesmos reservados para o processamento batch ou em lote através de scripts pbs.
Para submeter uma análise você precisará:
- Realizar conexão remota no cluster (veja a seção Conexão Remota e Transferência de arquivos no cluster).
- Elaborar o seu script pbs, especificando adequadamente os recursos necessários e os comandos necessários da sua análise.
- Submeter o script pbs.
- Monitorar o job.
- Conferir e tratar os resultados.
4.1 O script pbs
Como dito o script pbs nada mais é que um conjunto de instruções sequenciais.
Normalmente estes scripts são elaborados em shell script que deverá ter os comandos formando um roteiro a ser executado. O script pbs, além do roteiro, precisa especificar os recursos que serão necessários para execução deste roteiro.
A seguir mostraremos exemplos utilizando Bash que é um interpretador de comandos muito utilizado na construção de scripts.
Diferentemente de um bash convencional, em scripts pbs devemos incluir as diretivas #PBS que são responsáveis pela especificação de recursos necessários para execução deste roteiro. Estas diretivas são definidas utilizando os comentários do bash iniciando-se com #PBS e definindo formatos específicos para cada tipo de informação que será interpretada. Nos exemplos, ficará mais claro.
Exemplo 1 – Um script pbs básico
Temos abaixo um exemplo de script pbs feito em bash. Este é um exemplo genérico, sem qualquer utilidade prática. Serve apenas para ilustrar os principais componentes de um script pbs.
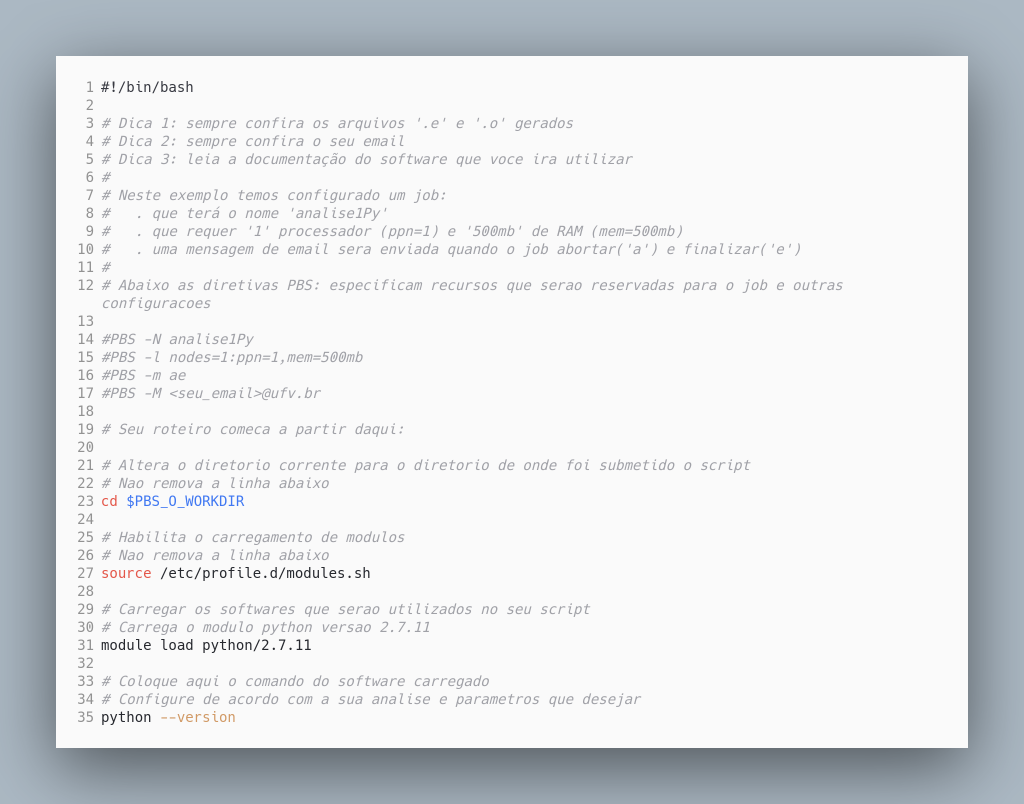
A linha 1 define que o interpretador utilizado será o bash.
Nas linhas 3-22 temos comentários bash, que são iniciados com #. Os comentários entre as linhas 3-12 são comentários comuns com qualquer informação textual que possam ser relevantes ao utilizador. Neste exemplo, os comentários são texto livre descrevendo as especificações do script em questão. No entanto, nas linhas 14-17 os comentários são diretivas PBS que serão interpretadas e entendidas pelo gerenciador de recursos. As configurações nestas diretivas são muito relevantes e devem ser definidas com atenção. Nestas diretivas são especificados os recursos computacionais necessários, e que devem ser reservados, para a execução do seu job.
As diretivas possuem sintaxe específica. Então, atenção a cada caractere digitado nas diretivas #PBS. Vejamos a explicação para cada diretiva utilizada:
- A diretiva
#PBS -Nespecifica o nome do job no sistema de filas. Veja a linha 13,#PBS -N analise1Py, onde nós especificamos que o job possui o nome ‘analise1Py’. Este nome deve ser sugestivo porque identificará o job no sistema de filas e não pode conter espaços. - A diretiva
#PBS -lespecifica os recursos computacionais que deverão ser reservados para o job. Esta é a diretiva mais importante. Veja a linha 14,#PBS -l nodes=1:ppn=1,mem=500mb. Neste exemplo estamos dizendo ao PBS que a análise em questão precisará no máximo de 1 processador (ppn=1) e 500mb de memória RAM (mem=500mb). - A diretiva
#PBS -mespecifica as situações em que o PBS enviará as notificações por e-mail com respeito ao job. Veja na linha 15,#PBS -m ae, onde dizemos ao PBS que queremos ser notificados quando o job for abortado pelo PBS (opção ‘a’) ou quando ele finalizar a execução (opção ‘e’). Podemos ser notificados quando o job iniciar a execução (opção ‘b’):#PBS -m abe - Em complemento à diretiva
#PBS -mprecisamos especificar qual o e-mail de destino das mensagens. Isso é feito na diretiva#PBS -M. Veja na linha 16,#PBS -M <seu_email>@ufv.bronde deveremos especificar o e-mail. É importante que seja uma e-mail institucional. Se seu e-mail institucional forfulano.de.tal@ufv.brficaria assim a linha 16:#PBS -M fulano.de.tal@ufv.br
As linhas 23 e 27 não devem ser alteradas. A linha 23 é responsável por guardar a referência do diretório de trabalho no momento da submissão do script pbs e é muito útil na construção de referências relativas aos arquivos de entrada. A linha 27 é responsável para habilitar o carregamento de módulos.
No cluster os softwares são instalados e disponibilizados via módulos. Veja mais informações sobre utilização módulos na Seção Softwares/Módulos. Mas adiantando um pouco sobre módulos: eles permitem a modificação dinâmica do ambiente do usuário e é responsável pelo carregamento de softwares instalados. Quando desejo utilizar um determinado software primeiramente devo carregar o módulo apropriado antes de utilizar o software.
De fato, o roteiro propriamente dito começa após a linha 27. Neste exemplo, o nosso roteiro consiste em:
- Carregar o software python versão 2.7.11 (linha 31).
- E, apenas imprimir a sua versão (linha 35).
Após a construção do script pbs você deverá submetê-lo ao PBS.
Exemplo 2 – Especificando a fila de destino – fila qtime
Após construir um script pbs e submetê-lo ao PBS os jobs irão para alguma fila de processamento. No cluster temos algumas filas de processamento com características diferentes. Por exemplo, temos uma fila para jobs com execução rápida, que tem o nome de qtime; outra para jobs que requeiram muita memória, que tem o nome high_mem. Neste link você pode consultar as filas disponíveis e suas características.
A especificação da fila não é obrigatória. Caso não seja especificado nenhuma fila os jobs são submetidos para a fila padrão de processamento.
Para submeter para a fila qtime precisaremos:
- Especificar o recurso
walltime, na diretiva#PBS -l - E, explicitamente, definir a fila qtime como destino, usando a diretiva
#PBS -q qtime
Veja o exemplo abaixo:
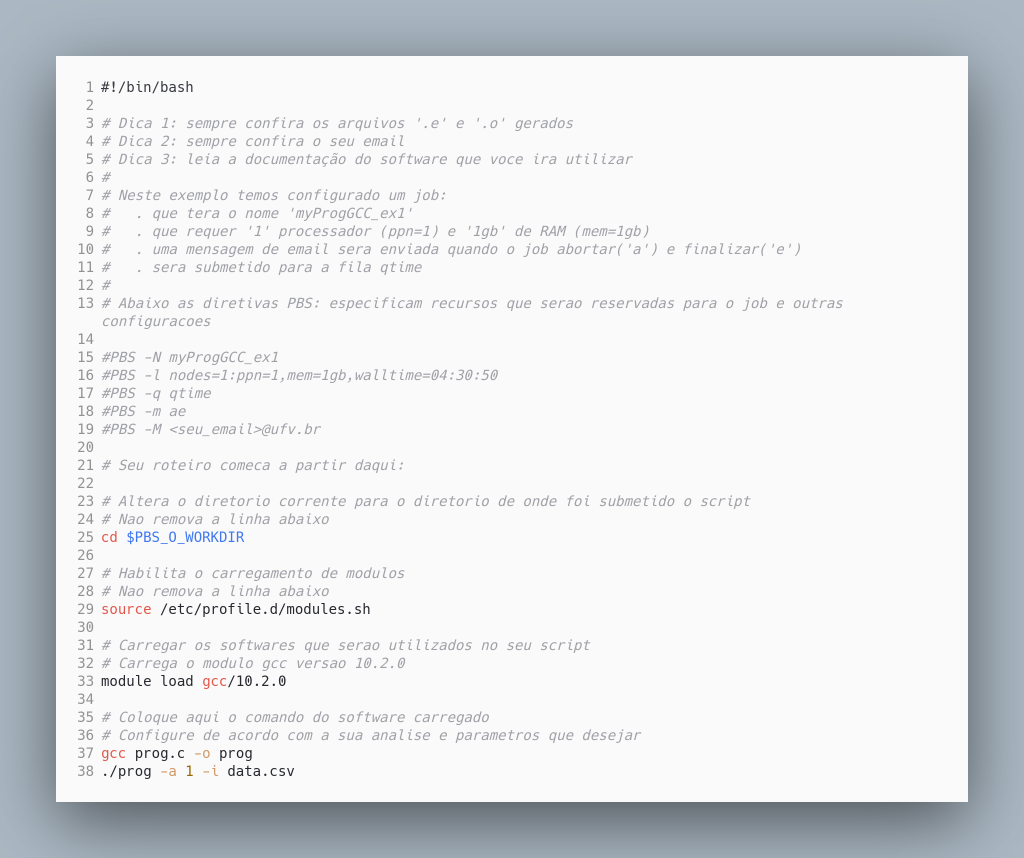
Basicamente temos duas alterações substanciais com relação ao exemplo anterior:
- A especificação do walltime:
#PBS -l nodes=1:ppn=1,mem=1gb,walltime=04:30:50 - A especificação da fila qtime:
#PBS -q qtime
Neste exemplo, o job especifica que precisará de no máximo 4h30m50s (walltime=04:30:50) para finalizar a execução. Especifica que precisará de 1 processador (ppn=1) e 1gb de RAM (mem=1gb).
Cada fila tem as suas especificidades. A fila qtime, por exemplo, só aceita jobs com um walltime máximo de 72 h. Por isso, é indicada para jobs com execução rápida. Ela possui prioridade sobre a fila padrão.
A fila padrão atende a maioria dos jobs submetidos ao cluster.
Exemplo 3 – Especificando a fila de destino – fila high_mem
Temos no cluster também a fila high_mem. Esta fila foi criada para jobs que requeiram uma quantidade substancial de RAM.
Ela aceita jobs requisitando no mínimo 25GB de memória RAM. Esta fila é bem limitada quanto ao número de jobs que cada usuário pode submeter nela e deve ser utilizada somente caso as outras filas não atendam às características de uso de memória para rodar a sua análise.
Para utilizá-la basta especificá-la como fila de destino na diretiva #PBS -q, conforme exemplo abaixo:
#PBS -l nodes=1:ppn=12,mem=30gb
#PBS -q high_mem
Neste exemplo, estamos especificando que o job precisará de 12 processadores (ppn=12) e 30gb de RAM (mem=30gb). E, que deverá ser submetido para a fila high_mem.
Exemplo 4 – Especificando nós ‘standard’
Com a reimplantação do cluster no início de 2016, outros nós de cálculo foram adicionados para prover maior capacidade de hardware ao cluster como um todo. Porém, estes novos hardwares possuem configurações diferentes. Para a maioria dos casos isso não fará diferença.
Porém, alguns tipos de experimentos não podem ser realizados em máquinas com hardwares diferentes. Para estes casos, deve ser adicionado mais um argumento nas diretivas #PBS para “filtrar” as máquinas com o mesmo hardware. As máquinas com o mesmo hardware são especificadas com a característica STANDARD.
Veja o exemplo abaixo:

STANDARDA linha responsável para fazer a filtragem é a linha 12:
#PBS -l select=1:ncpus=2:features=STANDARD:mem=2gb
Neste exemplo, estamos especificando que o job precisará de 2 processadores (ncpus=2) e 2gb de RAM (mem=2gb). E, que somente nós com característica STANDARD (features=STANDARD) deverão atender ao job.
4.2 Submetendo um trabalho (job) ao cluster
Após construir o script pbs, especificando adequadamente os recursos nas diretivas #PBS e colocando nele o roteiro da análise, devemos de fato executar a análise de modo a ter os resultados.
Porém, o script pbs não deve ser executado diretamente no head node, tal como seria feita em uma máquina convencional. O script pbs, para ser executado deve ser submetido para o sistema de filas com um comando específico do PBS: qsub
Submeter um trabalho ao cluster é muito simples. Basicamente, basta executar o comando, conforme abaixo:
qsub <seu_script.pbs>
onde <seu_script.pbs> deve ser substituído pelo nome do arquivo contendo o código do seu script pbs. Por exemplo, se o arquivo que você deseja submeter se chama analise_mothur.pbs o comando ficaria assim:
qsub analise_mothur.pbs
Após submeter o job, você verá no terminal um identificador. Este identificador é atribuído pelo sistema de filas ao job que você acabou de submeter e é utilizado para acompanhá-lo no sistema de filas.
Inicialmente, o job pode não entrar em execução de imediato. Mas assim que tiver recursos disponíveis no cluster para executar o seu job ele entrará em execução.
Após submeter o job você deverá monitorar o seu job.
4.3 Monitoramento de um trabalho (job) no cluster
Além do comando qsub, que mostramos anteriormente, temos outros comandos muito importantes para o monitoramento dos jobs. Veja na Tabela 1 alguns dos principais comandos do PBS:
qsub | Para submissão de jobs |
qdel | Para remoção de jobs das filas |
qstat | Para exibe informações de filas e jobs |
Na Tabela 2 são exibidos alguns argumentos para utilizar os comandos:
| qsub <meu_script.pbs> | Submete o script pbs do arquivo <meu_script.pbs> |
qdel <job_id> | Deleta o job <job_id> especificado |
qstat | Exibe informação sobre filas e jobs |
qstat -a | Exibe todos os jobs no sistema |
qstat -anu <seu_login> | Exibe todos os jobs pertencente ao usuário <seu_login> |
qstat -f <job_id> | Exibe todas as informações conhecidas sobre o job <job_id> especificado |
Nestes exemplos:
- <meu_script.pbs> deverá ser substituído pelo nome do arquivo a ser submetido.
- <seu_login> deverá ser substituído pelo seu login de acesso ao cluster.
- <job_id> deverá ser substituído pelo identificador do job no sistema de filas
Além destes comandos temos alguns utilitários. Eles foram elaborados pela equipe do Serviço de Apoio ao Desenvolvimento Científico (SDC) para auxiliar no monitoramento dos jobs em execução. E, também, para auxiliar na especificação de recursos de hardware nos scripts pbs. São o comando jinfo e hinfo
O comando ‘jinfo’
Este utilitário exibe alguns dados de utilização de recursos de um determinado job. Mostra a quantidade de memória RAM solicitada e a quantidade de RAM utilizada. Mostra também a quantidade de cpus(%) solicitada e a quantidade de cpus(%) sendo utilizada. Este utilitário também mostra a adequação de recursos do job, alertando o usuário caso o job utilize menos ou mais recursos do que foi definido no seu script pbs.
Para utilizá-lo basta digitar no seu prompt o seguinte comando:
jinfo <job_id>
Onde <job_id> deve ser substituído pelo identificador do job a ser verificado.
Uma das dificuldades que muitos usuários enfrentam é saber definir adequadamente a quantidade de processador e memória RAM que deve ser especificada no seu script pbs. Este utilitário foi elaborado com o intuito de auxiliar nesta tarefa.
É importante destacar que os valores utilizados de processador e RAM podem variar ao longo do tempo dependendo do tipo de tarefa que é realizado na análise. Por isso, é importante utilizá-los, quando necessário, em alguns momentos da execução do seu job.
O comando ‘hinfo’
Este utilitário mostra os recursos de memória RAM e processadores disponíveis em cada nó ativo do cluster.
Para utilizá-lo basta digitar o seguinte comando no seu prompt:
hinfo
Ele foi elaborado para auxiliar no dimensionamento da quantidade de recursos a ser requerido no script pbs a fim de diminuir os trabalhos que ficam em fila.
Por exemplo, suponha a situação onde alguns jobs estão em fila porque requerem 8gb de memória RAM para ser executado. E, existem vários nós de cálculo com 7gb de memória RAM disponível (o que pode ser visto utilizando o comando hinfo). Neste caso, se o processo puder ser executado com 7gb de memória RAM, e se esta quantidade de memória fosse especificado no script pbs, ele não entraria na fila. O mesmo raciocínio é feito para o uso de processadores.
5. Softwares/Módulos
No ambiente do cluster da UFV, os softwares são instalados e disponibilizados por meio de módulos, que permitem o carregamento dinâmico de configurações específicas para cada aplicação. Esse sistema facilita o carregamento, descarregamento e organização de diferentes versões de programas, bibliotecas e ferramentas científicas.
Cada módulo contém as instruções necessárias para ajustar variáveis de ambiente como PATH, LD_LIBRARY_PATH, entre outras, garantindo que o software funcione corretamente sem interferir em outras aplicações.
Todos os módulos instalados e disponibilizados pela DTI são autocontidos, ou seja, incluem todas as configurações e dependências necessárias para executar corretamente a aplicação que dá nome ao módulo. Isso assegura que o usuário possa utilizar o software de forma imediata e confiável, sem necessidade de ajustes adicionais no ambiente.
O uso de módulos é especialmente útil para:
- Alternar entre diferentes versões de um mesmo software;
- Evitar conflitos entre dependências;
- Atender às demandas específicas de projetos distintos.
A seguir, apresentamos uma tabela com os principais comandos utilizados para gerenciar módulos no cluster e exemplos práticos de como utilizar cada comando no cluster.
Comandos Úteis para Gerenciamento de Módulos
| Comando | Descrição | Exemplo |
|---|---|---|
module avail | Lista todos os módulos disponíveis no sistema | module avail |
module load <nome> | Carrega o módulo especificado para o ambiente atual | module load gcc/4.8.3 |
module list | Exibe os módulos atualmente carregados | module list |
module unload <nome> | Remove um módulo previamente carregado | module unload python/2.7.11 |
module purge | Remove todos os módulos carregados no ambiente | module purge |
module avail
Lista todos os módulos disponíveis no sistema. É o primeiro passo para descobrir quais softwares e versões estão instalados e prontos para uso.
Exemplo de Uso:
Para consultar todos os módulos disponíveis, digite no terminal:
module avail
# Listando módulos disponíveis $ module avail ------------------- Global Aliases --------------------------------- ncbi-blast-database/v5 -> ncbi-blast-database/v5.03.2025 ------------------- /home/username/privatemodules ------------------- braker/2.1.6 omnet++/5.4.1 gurobi/9.1.2 ------------------- /data/git/global-modules: ----------------------- abricate/1.0.1 megacc/10.1.7 abyss/2.0.3 miniconda3/23.3.1 mothur/1.47.0 perl/5.38.2 python/3.11.2
Cada item na saída deste comando (por exemplo, braker/2.1.6) é um módulo que poderá ser carregado e utilizado.
Os arquivos de módulo – chamados de modulefiles – seguem o padrão de nomenclatura nome/versão, como por exemplo mothur/1.47.0 ou python/3.11.2. Esse formato facilita a identificação e o carregamento de versões específicas de cada software.
Para consultar todos os módulos disponíveis que contenham “java” no nome digite no terminal:
module avail java
# Listando módulos que contenham a palava "java" $ module avail java ------------------- Global Aliases --------------------------------- ------------------- /data/git/global-modules: ----------------------- java/jdk1.8.0_101 java/jdk17.0.8 java/jre1.7.0_67 java/jdk1.8.0_241 java/jdk20.0.2 java/jre1.8.0_66 java/jdk11.0.7 java/jre1.6.0_05-p java/jre1.8.0_162 (D) tensorflow-java/1.13.2 tensorflow-java/1.15.0 (D)
module load
Após consultar os módulos disponíveis, com o comando module avail, você deverá carregar um módulo específico para o ambiente atual, tornando o software imediatamente utilizável na sessão. Esse comando deve ser utilizado antes de executar um programa, compilar um código ou rodar scripts que dependem de softwares específicos.
O comando segue o seguinte padrão:
module load <modulefile>
Onde <modulefile> é o nome de um módulo qualquer.
Exemplo de Uso:
Para utilizar o software R na versão 4.4.1 precisaremos antes carregar o módulo apropriado. Isso poderá ser feito utilizando o comando:
module load r/4.4.1
Após digitar o comando acima, o software R na versão 4.4.1 será carregado no seu ambiente e estará disponível para uso.
Observação: É importante notar que os módulos carregados ficam disponíveis apenas na seção atual.
module list
Exibe os módulos que estão atualmente carregados na sessão do usuário, permitindo verificar quais softwares estão ativos no ambiente.
Exemplo de Uso:
module list
# Ambiente Inicial $ module list No Modulefiles Currently Loaded. # Carregando módulos $ module load mothur/1.44.3 # Listando módulos carregados e suas dependências $ module list 1) mothur/1.44.3
No exemplo acima, temos um ambiente sem módulos carregados. Em seguida carregamos o módulo mothur/1.44.3 e certificamos com o comando module list que ele de fato foi carregado corretamente.
module unload
Após carregar um módulo você poderá descarregá-lo para, carregar outra versão do software, por exemplo. O comando module unload remove um módulo específico do ambiente atual, desfazendo as alterações nas variáveis de ambiente daquele módulo.
O comando segue o seguinte padrão:
module unload <modulefile>
Onde <modulefile> é o nome de um módulo previamente carregado.
Exemplo de Uso:
Suponhamos que tenhamos carregado o software python versão 3.7.4, com o comando module load python/3.7.4. E, agora desejamos utilizar o python versão 2.7.17. Para isso, basta descarregar o módulo do python/3.7.4 e carregar o módulo python/2.7.17. Isso seria feito com os comandos abaixo:
# Carrega python versão 3.7.4 para análise que requer Python 3 $ module load python/3.7.4 # Fez todas as análises utilizando Python 3... # ...mas uma parte de código legado precisa rodar com Python 2 # Descarrego o pyhon/3.7.4... $ module unload python/3.7.4 # ... e carrego o pyhon 2.7.17 $ module load python/2.7.17
Após digitar os comandos acima, teremos o python versão 2.7.17 carregado no seu ambiente.
module purge
Se quiser remover todos os módulos carregados na sessão atual, restaurando o ambiente ao estado inicial utilize o comando:
module purge
Após o executar o comando, nenhum módulo permanece carregado voltando o ambiente volta ao padrão.
Exemplo de Uso:
# Carregando módulos $ module load gcc/4.8.3 $ module load python/2.7.11 # Listando módulos carregados e suas dependências $ module list 1) gmp/5.1.0.3 2) mpfr/3.1.1 3) mpc/1.0.3 4) isl/0.12.2 5) cloog/0.18.1 6) gcc/4.8.3 7) python/2.7.11 # Limpando ambiente $ module purge $ module list No Modulefiles Currently Loaded.
6. Contato
Críticas construtivas e sugestões para o aprimoramento deste material são sempre bem-vindas. Para isso, solicitamos que seja aberto um chamado no Sistema de Abertura e Acompanhamento de Chamados da DTI, onde sua contribuição será devidamente registrada e avaliada pela equipe responsável.